
Recently, we worked to build a data lake on Big Data for the insurance industry. We used the Cloudera.
Hadoop environment for this. Our client had the data of multiple insurance companies, which we combined into a single data model and stored it in Hive tables. On top of this model, we built some dashboards for domains like policy and claims.
Why a snapshot table?
One of the critical functionalities in the dashboards was to quickly get all the details regarding a policy after entering the policy number. This includes all the related parties, locations, insurable objects, events, etc. Since the data on Hive was in a normalized data model, we would have had to query more than 20 tables and perform various joins to get these details. This would have needed to be faster.
Hence, there were other options than building dashboards directly on transaction data. Hence, we decided to build a snapshot table for this.
Data Model
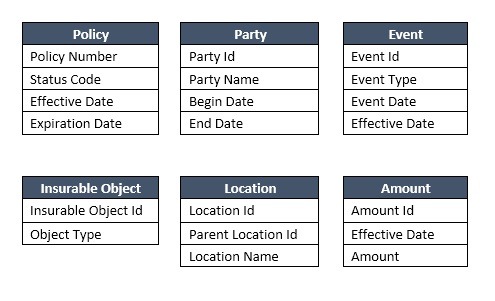
(I haven’t included all tables and all the columns, but there were more than 50 such tables with columns to join directly or indirectly with the policy table.)
Why HBase?
The first question was where to store the snapshot table. We decided that storing the snapshots on HBase would be a good option for the following reasons:
- Since the amount of data was more than a TB and likely to keep increasing, we needed a scalable storage system.
- Data retrieval was based on just one field (i.e. policy number) which we could use as a rowkey.
- After running the periodic snapshot generation script, in case of any updates in the source data, the snapshots will get updated at the corresponding rowkey (policy number).
Why JSON?
The second question was how to store the details coming from all the tables.
At first, we thought of just performing the necessary joins to get all the data and push the results into HBase. However, on further calculations, this proved to be infeasible. The issue was that,
- All the tables apart from the policy table had multiple rows for each policy number. For example, there were 3 parties, 10 events, 2 insurable object, 20 geographical locations and so on for some policies.
- Many of these fields were related to policy but not necessarily related to each other. For example, a geographical location may or may not be related to an insurable object.
This caused the results of the joins to grow exponentially to more than hundreds of trillions (more than 10^13). Even for a cluster, there were more feasible solutions.
Hence, we decided to store these details in JSON format. This way, the number of unrelated rows would just add and not multiply with each other.
Sample Row
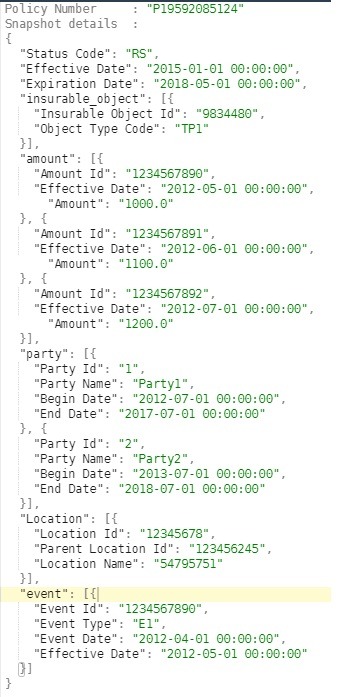
How do you generate the snapshot?
After deciding on the storage format, we needed to write a script to generate the snapshot table from the tables on Hive. For this, we made extensive use of Spark SQL from PySpark. We wrote queries in Spark SQL to retrieve data by joining the related subgroups of the required tables so the query results do not grow exponentially. After this, we wrote a user-defined function to convert the results into the ‘rowkey, json_snapshot’ format.
Storing the snapshot table on HBase with details in JSON format helped us reduce the required storage space and the retrieval time by a great margin. With this architecture, we were able to get sub-second latency for the policy details dashboard.


